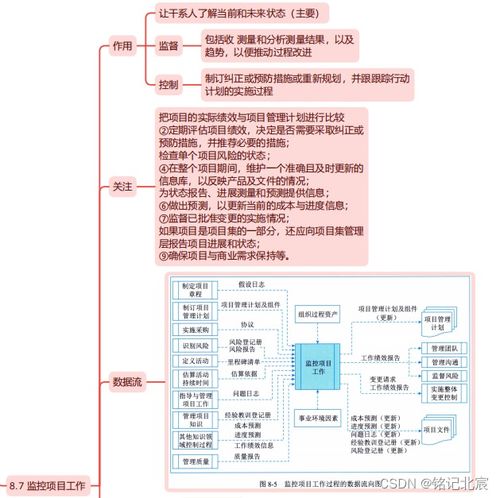
随着人工智能技术的快速发展,本地部署的大模型(Large Language Models, LLMs)在票据信息管理领域展现出巨大潜力。通过本地大模型提取发票信息,不仅提升了票据信息咨询服务的效率,还为企业数据安全和合规性提供了有力保障。
本地大模型能够通过自然语言处理技术自动识别和提取发票中的关键信息。无论是纸质发票的扫描件还是电子发票文件,大模型都能准确解析发票编号、开票日期、金额、购销方信息、商品明细等结构化数据。这种自动化处理大大减少了人工录入的错误和时间成本,特别适用于财务、税务和审计等高频使用发票的场景。
本地部署的大模型在数据安全方面具有显著优势。与云端服务不同,本地模型处理数据时无需将敏感发票信息上传至外部服务器,有效避免了数据泄露风险。对于涉及商业机密或个人隐私的票据,企业可以完全掌控数据处理流程,符合GDPR、个人信息保护法等法规要求。
在票据信息咨询服务中,本地大模型还能提供智能分析和决策支持。例如,模型可以自动归类发票类型(如增值税普通发票、专用发票)、识别异常发票(如重复报销、虚假发票),并生成可视化报表。咨询机构可以基于这些分析结果,为客户提供税务优化、成本控制和合规审计等专业建议。
实施本地大模型也面临一些挑战,如硬件资源需求高、模型训练和优化需要专业知识等。企业需根据自身数据量和业务复杂度选择合适的模型规模,并配备相应的技术团队进行维护。
随着大模型技术的不断成熟和开源社区的贡献,本地化票据信息提取将变得更加普及和易用。结合OCR(光学字符识别)和RPA(机器人流程自动化)技术,大模型有望实现端到端的票据管理自动化,重塑票据信息咨询服务的行业标准。